
APEX TRIGGER ACTIONS AND NEBULA TRIGGERS

In the first part of this article, we explored the value and importance of selecting a trigger framework which separates technical dependencies effectively.
This part is a deep dive into two of the most powerful and well established frameworks based around these principles:
Apex Trigger Actions Framework (Apache 2.0 license) - Maintained by Mitch Spano
Nebula Core - Nebula Triggers (MIT license) - Maintained by Aidan Harding and Nebula Consulting
Approach for Review
This article is broken down into the following sections:
- Objectives - motivations for the review
- Configuration in the Org - how triggers, classes and custom metadata are set up under each framework
- Functional Capabilities - features of each framework
- Performance - looking at resources and processing time for a typical transaction
- Project Setup - what's needed to get up and running
- Scratch Org Deployment Time - overhead for the framework to be deployed in a fresh scratch org
- Track Record - production usage and stability
- Conclusion
Objectives
Before getting into details, I want to be really transparent about my perspective in making this comparison. Some of this will apply to your organisation but some might not, so be mindful of this!
I started this comparison as I'm looking for a framework for a new (well, nearly new) org which will use a package-based development model with scratch orgs for development and CI. Config and trigger code for some core objects will be distributed across more than one package.
Broadly, our trigger framework requirements for this project are:
Core design requirements
- Framework must follow the one trigger per object paradigm
- Framework must support loose coupling between the org's triggers and handler classes, so these don't need to coexist in the same package
- Framework must allow consistently calling methods for all triggers, or at least be modifiable and extensible within the org. This is to allow us to easily call other frameworks which should run with every trigger (for example a logging framework)
Trigger handler feature requirements
- Trigger handler methods must run in a defined sequence
- It should be straightforward to suppress trigger handler invocation for data loads carried out by an ETL integration user
- It should be possible to identify trigger recursion and prevent a trigger processing more than a specified number of times
Non-functional requirements
- Performance impact should be minimal
- The framework itself should be lightweight to reduce time to build a scratch org
- The framework should be established and proven to be stable
These objectives influenced the choice of solutions I reviewed as well as the final decision we made - relevance of each of these and other factors are likely to be different for your org.
Configuration in the Org
OK, let's first take a look at how features are implemented using each of these frameworks.
Both use a similar mechanism to enable the org's custom code to be invoked by a trigger:
- The trigger itself should execute on all trigger contexts, and should include a single line calling a method from the framework
- The actual logic the trigger will call is defined in classes (I'll call these handler classes) implementing one or more interface from the framework - there's one interface available for each trigger context.
- Custom metadata records are set up for each context and method the trigger should call. Order can be specified on each record to control the sequence of processing
To test out the main capabilities, I've implemented some basic features around account and contact automation. Code I used to test each framework (functionally more or less the same) is in the Gists below:
Apex Trigger Actions Triggers and Handlers
Nebula Core Triggers and Handlers
NB: My classes are written in an intentionally crappy way without checks that records haven't been updated already as well as various other clangers. It's worth mentioning that while I've included this to show how recursion can be controlled through mechanisms in the framework in the case of Apex Trigger Actions, it's far better to avoid these issues by checking conditions to determine whether a record needs to be updated in the logic of the class. Whilst a helpful crutch at times, hard recursion stops can make future debugging more complex, and behaviour following a transaction rollback or multiple changes in the same transaction (for example updating a record twice in an apex test) can be inconsistent with the effects of a simple change.
Custom Metadata (Apex Trigger Actions)
Setup in Apex Trigger Actions involves first setting up a custom metadata record "sObject Trigger Setting" corresponding to the trigger itself:
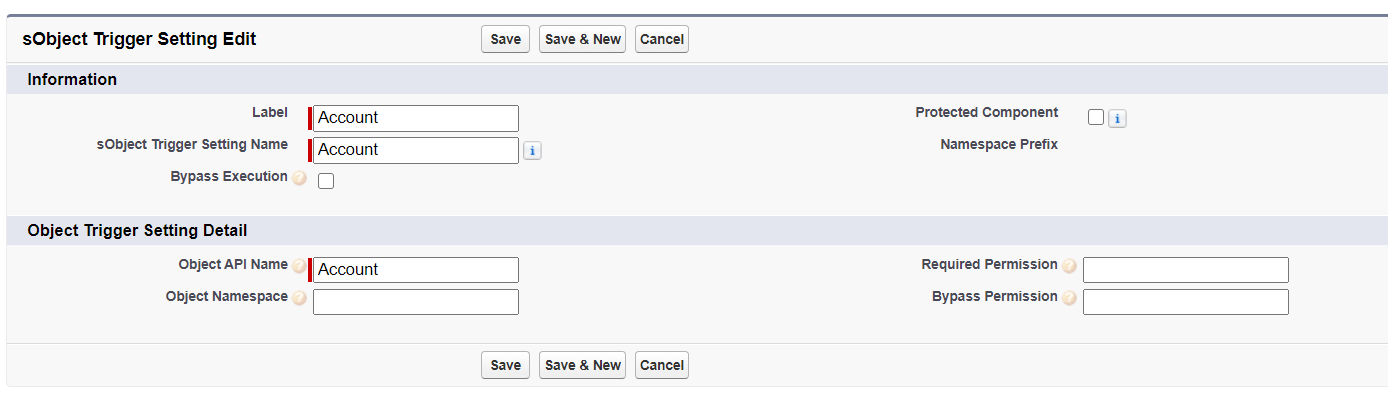
This level allows us to control deactivation settings which apply to all triggers on an object.
Once a trigger level record is set up, custom metadata records to control calling of handler methods ("Trigger Actions") are set up in a separate custom metadata type, and linked to parent settings with a lookup corresponding to the relevant context:
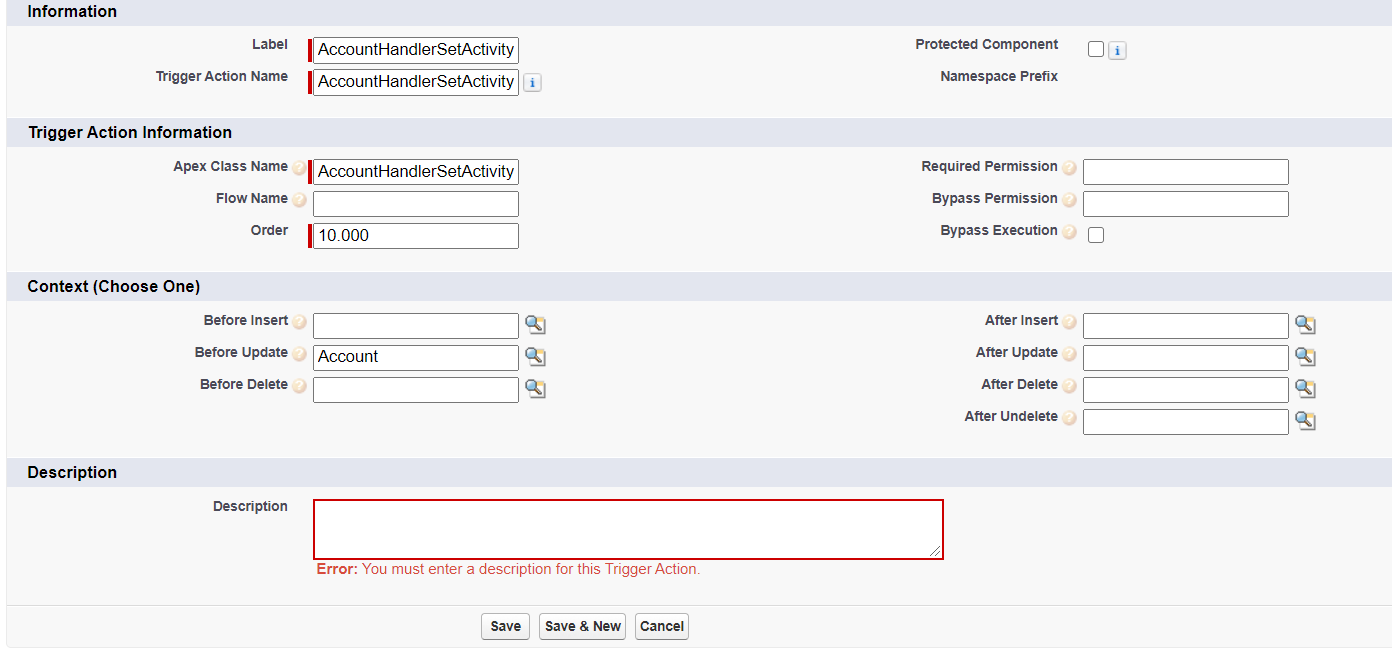
Notice the validation rule making description mandatory which is enabled by default - nice to encourage self-documenting metadata!
The lookups to sObject Trigger Setting make the page layout for this a good summary of automation on the object:
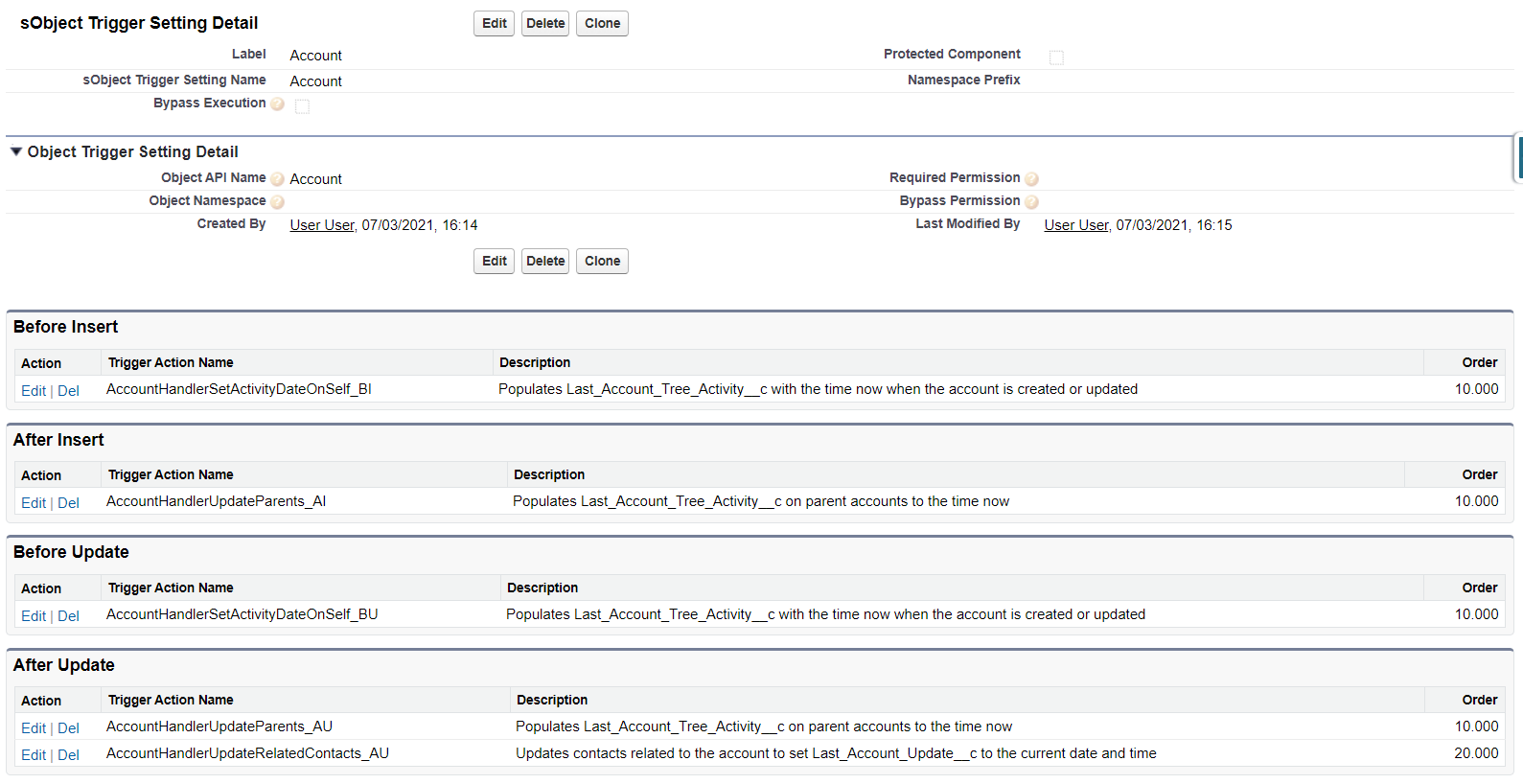
Custom Metadata (Nebula Triggers)
Nebula Triggers uses a simple and clear custom metadata data model, which also requires one record per method and trigger context. Setting up a record is straightforward:
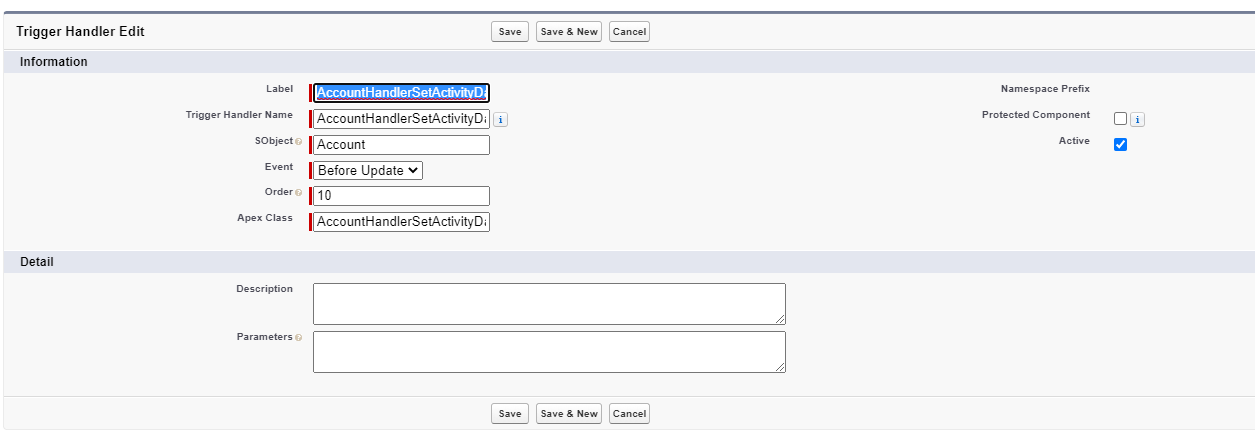
And the metadata list view gives us an overview of trigger automation in the org:

Functional Capabilities
With everything in place now, let's take these for a spin!
To state the (hopefully) obvious, both these frameworks worked consistently for me and did exactly what they're built to do. For brevity, I'm not going to detail my experiences with basic aspects of functionality - method calls, order of execution, correlating between metadata and classes etc. From what I've seen, the current versions of both frameworks do these perfectly.
I'll concentrate instead on value add features provided by each framework.
Extra Features (Apex Trigger Actions)
Bypassing logic
As mentioned above, Apex Trigger Actions offers multiple ways to dictate whether a defined trigger action is carried out for a given circumstance.

At both trigger level, and handler method / trigger action level, it's possible to do any of the following:
- Deactivate completely ("Bypass Execution" flag)
- Run only for users with a specified custom permission ("Required Permission")
- Run only for users without a specified custom permission ("Bypass Permission")
- Set (and unset) operations which should be bypassed by calling central framework methods with the trigger or class name. At time of writing, this feature is being extended to calls from flows too.
The first three of these can be done with simple changes to the custom metadata records, so are clear and accessible for admins.
For our context, using a Bypass Permission at the object level for all objects allows us to deactivate triggers for data loads carried out by an integration user. A few tests confirmed these features work as designed.
The custom permission approach also opens an interesting opportunity for piloting / beta testing of new features - new trigger actions could be deployed and set up initially with a custom permission for the feature assigned as Required Permission. The custom permission could be allocated only to those users participating in the pilot, and the feature later extended to everyone just by removing the Required Permission. Nice!
Recursion protection
The functionality in the code snippets intentionally includes recursion to illustrate capabilities of Apex Trigger Actions.
In my examples, the account trigger will update related contacts following an account update (the AccountHandlerUpdateRelatedContacts class), but a contact insert/update will also update the account record it's associated to (the ContactHandlerUpdateAccount class). With nothing to prevent this recursion, doing something like creating a contact would lead to errors like this:
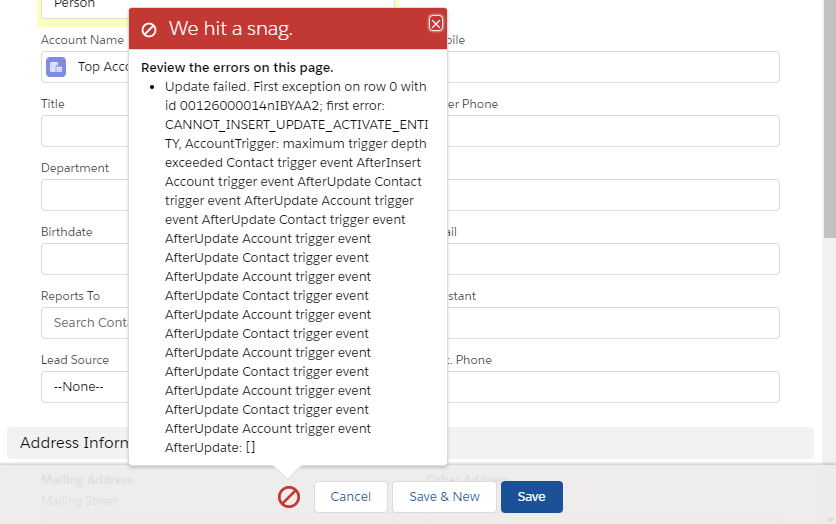
When the logic of a recursion is difficult to pin down, a common technique is to allow a method to be run only a specified number of times - I've shown a simple variant of this approach in the example code for Nebula Triggers.
Apex Trigger Actions contains built in functionality to manage this without extra logic being needed in the org. The idToNumberOfTimesSeenAfterUpdate static map in the TriggerBase class can be used to check whether a record has already been processed.
Code in AccountHandlerUpdateParents which identifies accounts for update (no recursion protection here):

Refactored code using idToNumberOfTimesSeenAfterUpdate to avoid updating the same account more than once:

A nice advantage of this technique is that triggers can run recursively when records haven't previously been processed. In the example above this will allow parent, grandparent, great-grandparent accounts to be updated with recursive trigger runs, but the code will protect the same account being updated more than once.
With counts maintained in the map, it's helpful too to be able to allow recursion but only a specified number of times.
It's worth noting that recursion control should be stopped in this way as a last resort - in almost all cases it's preferable to check conditions in the code to determine whether a record should be updated (in the example above, querying for the account and checking values fields to be set by the trigger to check whether an update has already happened).
Coordination of flows
Apex Trigger Actions offers the ability for a trigger action to invoke a flow.

This allows auto-launched flows exposing input and output collection variables for new and old records to be called (in this sense, the approach is very similar to the process builder + flow approach which has been promoted by Salesforce until fairly recently). There are a couple of specific features which improve what's possible over the traditional process builder based recommendation:
- An apex action is available to get an old (pre-update) version of a record for comparisons. This uses the cached record so doesn't contribute to query limits, and is safe to call in a loop
- Support for a newListAfterFlow output variable, which can be populated in a before context to express changes to the current records which will be made without DML. This allows auto-launched flows to be used to do before-context operations in a similar way to before-context triggers
- Options to either allow or prevent automation recursion. With process builder, built-in mechanisms to prevent recursion always apply
The mechanisms available can be used to create trigger actions and flows like the one below (image taken from the repo readme):

This is useful to have, has clear benefits over process builder and flow, and offers a straightforward migration path to eliminate process builder from any process builder + flow automation you have already. That said it's important to compare this not just to the legacy technique it might be replacing, but the current best native solution for config-based record automation, record-triggered flows.
Record-triggered flows are now available for both before and after contexts, and have the advantage that explicitly handling collections of records isn't necessary (Salesforce will apply bulkification automatically). For comparison, the functionality of the flow above could be implemented using the before-context record-triggered flow below:

Record-triggered flows also open the door to addressing a wider variety of use cases, for example comparisons against related objects, which can't be done efficiently using auto-launched flows operating on collections.
Of course using record-triggered flows together with Apex Trigger Actions means flows wouldn't be shown clearly alongside the trigger actions and can't be sequenced between them. Record-triggered flows have their own disadvantages to bear in mind (order of execution not guaranteed for example), but it's worth considering these are being promoted actively as the best approach for record automation using config, and continued improvements are likely.
NB: I've deliberately sidestepped giving an opinion around whether triggers and config automation should be combined on a single object. This is a big topic but I'd recommend thinking carefully about whether this is right for your org even with everything coordinated with Apex Trigger Actions.
Extra Features (Nebula Triggers)
It's worth noting first that I'm only looking here at mechanisms directly related to trigger operations. There's a whole lot more to Nebula Triggers, much of which is included in the pre-requisites required for the framework - Lazy Iterator, SObject Cache, SObject Index and other frameworks/tools are included and available to use in the minimum set of components needed for the framework.
Bypassing logic
Nebula Triggers offers the ability to deactivate handler methods by changing an "Active" flag on the custom metadata record. This provides a simple way to manually deactivate methods temporarily for a system deployment for example.

Whilst there isn't as much flexibility around mechanisms to bypass execution as in Apex Trigger Actions, this feature will be sufficient for many environments.
PAssing parameters to handler classes
There's a nice feature included in Nebula Triggers to specify a list of JSON parameters in the custom metadata records which will initialise variables in the handler class, allowing this to adapt to different calling contexts.
A JSON can be added to the "Parameters" field with each variable which should be initialised with a value:

Parameters in the JSON will be serialised into class variables as it's instantiated. Variables should have visibility of public (or global if using the package):

![]()
This could be a helpful tool in a scenario like a multi-org deployment, where classes called through the same context need to operate with different inputs.
Performance
Being called as part of most automations in the org it's vital that a framework doesn't get in the way.
I'm happy to say both frameworks perform adequately and, in my view, should scale relatively well without significant impact on system resources. The only contributions to platform limits are CPU time and the query rows from metadata queries - unlikely to consume more than a few of the 50,000 allowed.
The considerations around each framework for complex orgs are a little different though. The timelines below show a breakdown of a typical simple transaction using both frameworks, a contact update which updates account, causing account trigger to also fire.
Note that graphics are taken from the wonderful Apex Log Analyzer from Financial Force - can't recommend this enough!
Transaction Profile - Apex Trigger Actions

In Apex Trigger Actions, metadata is queried at the beginning of every before and after context for each trigger, so four times in this example, but other processing within the framework is relatively light. This means a simple, non-cascading, trigger performance is very efficient.
For more complicated triggers there could be far more metadata queries. The queries are relatively optimised and in the scheme of things the numbers are small, but this could end up the less performant framework for complex cascading examples.
Transaction Profile - Nebula Triggers
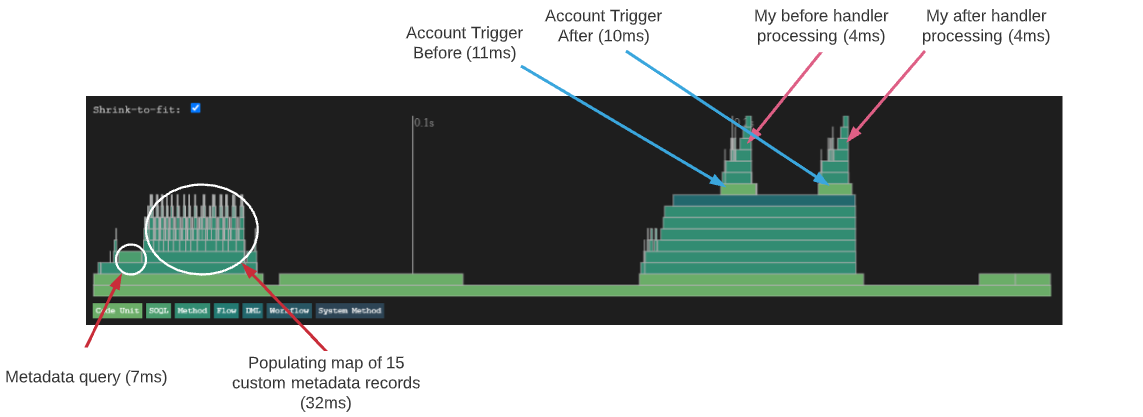
You can see the approach for performance-intensive activities here is actually quite different. Nebula Triggers will first query all metadata trigger records in the org and cache these in a map to be referenced throughout the transaction.
This approach means only a single metadata query per transaction, so once this initial process is complete other processing is very efficient (reflected in the shorter time taken for account before/after triggers - labelled with blue arrows). Relative to Apex Trigger Actions, this design should improve complex transaction performance with many cascading triggers (provided there are few handler methods in the org), but make things a little slower for simple transactions.
It's worth considering the upfront processing time would be roughly proportional to number of trigger handlers in the org, so in an org with a very large number of trigger handlers this could become an issue. I haven't tested with these volumes but extrapolating performance for 15 actions (roughly 2ms per action), an org with 1000 trigger handlers could see an extra 2 seconds or so per transaction from the construction of the map. If you're considering this framework for a very large org I'd recommend further testing in this area.
NB: Performance in earlier versions of Apex Trigger Actions was significantly slower than the current implementation due to queries on metadata relationship fields (thanks Mitch for quickly adding improvements in this area). If you're using a version of Apex Trigger Actions taken from the master branch prior to mid-Feb 2021 I'd strongly recommend upgrading to the latest implementation.
Project Setup
The package architecture for the project I'm working on will be broken into three layers, each dependent on the previous one:
- Platform package, including the trigger framework as well as logging framework, testing frameworks etc
- Common package, for high level functionality shared between applications
- Series of application packages, containing features specific to each app
For the purposes of testing, I'm using two separate SFDX projects with either the Apex Trigger Action or Nebula Triggers framework metadata in the platform package folder, triggers in the common package, and trigger handlers in the application (simulating our planned setup for central objects like Account and Contact).
Including the Framework (Apex Trigger Actions)
Apex Trigger Actions Framework is made available as an open source project on Github (https://github.com/mitchspano/apex-trigger-actions-framework), and getting the source deployed into a scratch org was quick and easy - I just cloned the Git repo and copied the trigger-actions-framework folder into my project's platform package folder, which deployed successfully on first push.
Including the Framework (Nebula Triggers)
Nebula Triggers is made available in two free namespaced unlocked packages, allowing an install of either just the trigger framework itself or the full suite of Nebula Core capabilities. All source code for Nebula Core is also available at the open source repository https://bitbucket.org/nebulaconsulting/nebula-core/src/master/.
As well as the trigger framework itself, the full Nebula Core package and source repo include a number of general utilities to support design patterns employed by the team at Nebula. I decided that for us, including the trigger framework source code directly in our project would be preferable. The main reason for this is that for the unlocked package to call methods handler in the org, these must be set to global. This is an understandable requirement but a slight security compromise, as trigger handler classes will be visible to, and could be called by, all other installed apps as well.
Actually getting minimal metatdata for the trigger framework from the repo is straightforward - the "nebula-triggers" folder of the repository contains symbolic links to the framework folder and the two library component folders also needed.
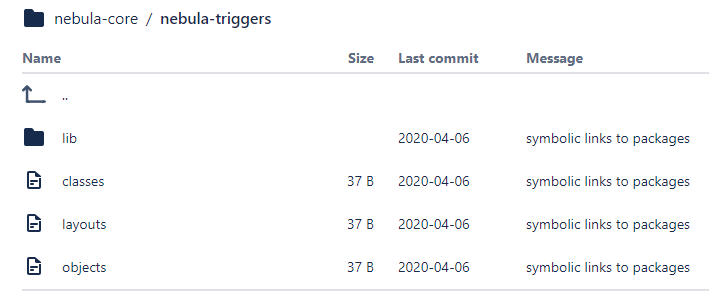
Scratch org Deployment Time
As the client I'm working with will adopt a package based development model, there will be lots of scratch org builds taking place. Being such a cornerstone of the architecture, the trigger framework will be included in the platform package and deployed as part of every scratch org build. Whilst we're exploring ways to avoid this needing to happen whilst a developer is waiting (the org snapshot pilot and the excellent set of CI tools in SFPowerScripts), I'd still like to ensure a build is as quick as possible.
The number of components in both frameworks is small (37 for Apex Trigger Actions and 52 for Nebula Core) and deployment times for both are comparable and completely acceptable - below 10 seconds in each case to deploy just the platform folder including all framework components.
Track Record
Another aspect which may influence choice between these options is how much use they've seen in production orgs, and how much attention and scrutiny the projects have had to give confidence in stability of the current version.
The first article introducing Apex Trigger Actions was published August 2020, whereas the first overview of the trigger framework in Nebula Core was published March 2018. More important though is known adoption they've had in production orgs. I asked both Mitch and Aidan to summarise their views on how and where their frameworks are used:
Apex Trigger Actions
"I created the Trigger Actions framework in an attempt to make it easier for developers to add new functionality by allowing them to write new classes instead of modifying existing ones, and easier for other team members to understand that functionality by providing a view of all of the automation on a given sObject in one place. The original framework was published in the fall of 2020, but the addition of support for flows was added in early 2021. The framework was created as an open-source project, and is currently being used to support Salesforce projects within Google. I am very excited to share this framework with the world - it can help organizations increase the speed at which they deliver new functionality and bridge the gap between the declarative and the programmatic sides of the Salesforce platform."
Mitch Spano (Google / author of Apex Trigger Actions)
Nebula Triggers
"My main motivation for starting with this sort of trigger framework was the open-closed principle - the custom metadata framework allows you to add triggers by adding code + metadata rather than ever having to edit your existing code. It was only later when Unlocked Packaging came along that I realised how perfectly it fit with that.
That first version was written as a managed package in March 2017. That was then rewritten to the Nebula Core version in March 2019. Nebula Core is currently installed in 59 production orgs."
Aidan Harding (Nebula Consulting)
It's worth mentioning that both of these frameworks are maintained by respected and active members of the community who continue to support and extend these projects. The few issues I found using Apex Trigger Actions were addressed and available in the repo within hours.
Conclusion
These projects share a lot of strengths and either one is an excellent choice for a simple framework to play well with unlocked packages.
Both frameworks serve the fundamental requirement of breaking the dependency between triggers and logic in an effective way. Both are easy to set up, perform adequately, and control sequencing effectively.
Apex Trigger Actions might be the right choice for its additional features bypassing and recursion control. It may also be appropriate if you already have auto-launched flows currently called by process builder and are looking to decommission process builder without the need to rearchitect these flows. The smaller number of components needed for Apex Trigger Actions makes it a little faster to deploy.
Nebula Triggers could be a good option if you'd value the extra features in the ecosystem of Nebula Core. There's a lot of cool things included - from methods bringing array functions to apex (Lazy Iterator) to time savers like setting SObject maps using any field or composite key from the records (SObjectIndex). Some components from Nebula Triggers are common to other capabilities in the project, and it may be of interest to explore what else Nebula Core could add to your org.

In many ways this isn't really a fair comparison - it's a little like choosing between a big juicy apple to a basket of fruit. If you're wondering what we went with for our project, we decided on balance that Apex Trigger Actions was right, the bypass permissions being the main factor which swayed the decision.
Finally just to mention if you find yourself with either of these frameworks in your org you're probably in a better place than most! Either one is likely to serve you well going forwards, especially if unlocked packages are part of your strategy or ambitions.